
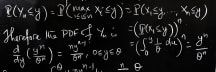
On the Stochastic Gradient Descent Algorithm (SGDA)
In this post, I shall talk about the well-known SGDA. It is an algorithm which provides an iterative procedure to locate solutions of an optimization problem and has wide applications in ML!

On the Stochastic Gradient Descent Algorithm (SGDA)
This post will be a culmination of:
1. Basic notion of SGDA.
2. Key concepts necessary to understand SGD:
3. The algorithm.
4. Benefits & Challenges of SGDA.
5. An example in the field of ML with a code snippet.
So please stick around till you reach the snippet!
1. Basic notion of SGDA:
- SGDA is an optimization algorithm that's widely used in ML/Optimization tasks.
- It's an extension of the traditional gradient descent method that aims to efficiently minimize (or maximize) an objective function.
- It iteratively updates the model's parameters based on small random subsets of the data.
- This approach allows SGD to handle large datasets more efficiently compared to traditional gradient descent.
2. Key concepts necessary to understand SGDA:
- Objective Function: In ML, the objective function represents the "cost" or "loss" associated with the model's predictions compared to the actual data. The goal is to minimize this function to find the best-fitting model parameters.
- Gradient: The gradient of the objective function indicates the direction of steepest increase. In optimization, the gradient points towards the optimal solution. Minimizing the negative gradient moves the solution closer to the minimum of the function.
- Learning Rate: The learning rate 'α' determines the step size of parameter updates. A large learning rate might lead to overshooting the minimum, while a small learning rate can slow down convergence. It's a hyperparameter that needs to be carefully tuned.
- Batch Size: In traditional gradient descent, the entire dataset is used to compute the gradient in each iteration. In SGD, a random subset (mini-batch) of the data is used. The size of this subset is the batch size.
3. The SGD Algorithm:
What is the underlying problem?
Given an objective function 𝒻(θ) that needs to be minimized (or maximized) with respect to parameters θ, and a dataset 𝒟 consisting of data points (xᵢ,yᵢ).
- Step 1
Initialization: Choose an initial guess for the parameters θ₀.
- Step 2
Hyperparameters:
• Choose the learning rate α.
• Choose the number of iterations T.
- Step 3
Iterations: For t=1 to T:
• Randomly shuffle 𝒟.
• Compute the gradient of the loss function w.r.t θ using (xᵢ.yᵢ): ∇𝒻ᵢ(θ)=∂/∂θ Loss(yᵢ,𝒻(xᵢ;θ)).
• Update the parameters using the stochastic gradient and learning rate: θ(t+1)=θ(t)−α∇𝒻ᵢ(θ(t)).
- Step 4
Convergence check: Monitor the change in the objective function or the norm of the gradient. Stop if the change is below a predefined threshold, indicating convergence, or if the maximum number of iterations T is reached.
- Step 5
Output: Return the final parameter values θ(T), which are the estimated optimal parameters that minimize (or maximize) the objective function.
Some notes on SGDA:
- The objective function 𝒻(θ) represents the loss or cost function that measures the discrepancy between model predictions and actual data.
- The gradient ∇𝒻ᵢ(θ) represents the direction of steepest increase of the loss function with respect to the current data point.
- In practice, stochastic gradient descent is often implemented using mini-batches (subset of the dataset) to balance computational efficiency and gradient noise.
- Learning rate α determines the step size of each update. It's a critical hyperparameter that affects convergence.
- The convergence criterion could be based on the change in the objective function or the norm of the gradient. It ensures that the algorithm stops when further updates don't result in significant improvements.
4. Benefits of SGDA:
- Efficiency: Using small mini-batches instead of the entire dataset makes computations faster and requires less memory, making SGDA suitable for large datasets.
- Stochastic Nature: The randomness introduced by using mini-batches adds noise to the optimization process. This noise can help escape local minima and explore the parameter space more effectively.
- Online Learning: SGDA can be used for online learning, where models are updated continuously as new data becomes available.
- Parallelization: SGDA can be easily parallelized since each mini-batch computation is independent.
Drawbacks/Challenges of SGDA:
- Learning Rate: Choosing the appropriate learning rate is crucial. A learning rate that's too high can lead to instability, and one that's too low can slow down convergence.
- Learning Rate Scheduling: Adaptive learning rate methods, such as AdaGrad, RMSProp, and Adam, adjust the learning rate during training to mitigate the need for manual tuning.
- Noise: While noise can help escape local minima, it can also lead to convergence to suboptimal solutions.
- Convergence: SGDA might converge to a solution close to the minimum, but not exactly at the minimum, due to the randomness and noisy updates.
- Batch Size: The choice of batch size affects the trade-off between computation time and convergence stability.
5. An example in the field of ML with a code snippet:
- Linear regression with SGDA.
- SGDA updates the parameters (slope and intercept of the line) based on the gradient of the loss function.
- The parameters converge to values that minimize the mean squared error.

Thank You for sticking around! See you in my next prost!
:)